Neue Studie testet die Anwendung maschinellen Lernens zur Erkennung von Lehnwörtern
Bislang unbefriedigende Ergebnisse unterstreichen die Komplexität der Sprachentwicklung.
Ein Forschungsteam der Pontificia Universidad Católica del Perú (PUCP) und des Max-Planck-Instituts für Menschheitsgeschichte (MPI-SHH) hat untersucht, inwieweit Algorithmen des maschinellen Lernens in der Lage sind, Lehnwörter anhand von Wortlisten einer einzigen Sprache zu erkennen. Die in PLOS ONE veröffentlichten Ergebnisse zeigen, dass die derzeitigen Methoden des maschinellen Lernens allein noch nicht ausreichen, um Lehnwörter zuverlässig zu erkennen und bestätigen, dass weitere Daten und spezifisches Wissen nötig sind, um eine der größten Herausforderungen der historischen Linguistik zu bewältigen.
Lehnwörter oder Fremdwörter, also Wörter die durch den direkten Transfer aus einer Sprache in eine andere gelangt sind, sind bereits seit Jahrtausenden Gegenstand in Sprachforschung und Philosophie. So diskutierte schon Sokrates in Platos Kratylos-Dialogen die Herausforderungen, die Lehnwörter für etymologische Untersuchungen darstellen. In der historischen Linguistik können Lehnwörter der Forschung helfen, die Entwicklung moderner Sprachen zu verstehen sowie kulturelle Kontakte zwischen verschiedenen linguistischen Gruppen nachzuvollziehen. Jedoch sind die Techniken, mit denen Lehnwörter erkannt werden können, bislang nur wenig formalisiert und setzen eine Vielzahl von Hintergrundinformationen voraus, die meist nur durch den Vergleich mehrerer Sprachen gewonnen werden können.

„Die automatisierte Erkennung von Lehnwörtern zählt bislang noch zu den komplexesten Aufgaben in der historischen Computerlinguistik“, so Johann-Mattis List, Leiter der Forschungsgruppe CALC am MPI-SHH und leitender Autor der Studie.
In der Studie versuchte das Forschungsteam maschinell nachzuahmen, wie in der Linguistik Lehnwörter identifiziert werden, wenn Daten aus nur einer einzigen Sprache vorliegen. Klingen die Laute, beziehungsweise die Art, wie sich die Wörter phonetisch zusammensetzen, für ihre Ausgangssprache atypisch, deutet dies oft auf jüngere Lehnwörter hin. Um zu überprüfen, wie präzise die Algorithmen Wörter als Lehnwörter klassifizieren, wurden die Modelle auf einer modifizierten Version der World Loanword Database, welche Lehnwörter aus 40 Sprachen verschiedener Sprachfamilien der ganzen Welt enthält, erprobt.

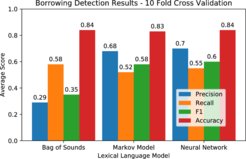
In vielen Fällen waren die Ergebnisse jedoch unbefriedigend, was vermuten lässt, dass die Erkennung von Lehnwörtern für die geläufigen Methoden des maschinellen Lernens noch zu komplex ist. In bestimmten Situationen, so zum Beispiel bei Listen mit einem hohen Anteil an Lehnwörtern oder bei Sprachen, deren Lehnwörter hauptsächlich aus einer einzigen Spendersprache stammen, zeigten die lexikalischen Sprachmodelle des Teams jedoch vielversprechende Ergebnisse.
„Nach diesen ersten Versuchen mit einsprachigen lexikalischen Entlehnungen können wir nun weitere Aspekte des Problems abstecken und zu mehrsprachigen und sprachübergreifenden Ansätzen übergehen", erklärt John Miller von der PUCP, einer der beiden Erstautoren der Studie.
„Unser computergestützter Ansatz wird zusammen mit dem Datensatz, den wir veröffentlichen, die Bedeutung computergestützter Methoden für den Sprachvergleich und die historische Linguistik in ein neues Licht rücken", fügt Tiago Tresoldi vom MPI-SHH, zweiter Erstautor der Studie, hinzu.
Die Studie reiht sich ein in die laufenden Bemühungen, eines der schwierigsten Probleme der historischen Linguistik zu lösen, und zeigt, dass sich die Erkennung von Lehnwörtern sich nicht allein auf einzelsprachliche Informationen stützen kann. Für die Zukunft planen die Forscherinnen und Forscher, besser integrierte Ansätze zu entwickeln, die mehrsprachige Informationen berücksichtigen.