Guidelines for a Standardized Data Format for Use in Cross-Linguistic Studies
The Cross-Linguistic Data Formats Initiative proposes new standards for linguistic data formats to facilitate sharing and data comparisons.
 using the guidelines given in the paper.")
A world map showing data points, for which the researchers plan to gather unified data (e.g., data that is directly comparable) using the guidelines given in the paper.
There is an increasing number of linguistic databases worldwide, raising the possibility of a vast network for potential comparative studies. However, these databases are generally created independently of each other, and often have a unique and narrow focus. This means that the formats used for encoding the data are often different and this creates real difficulties in effectively comparing data across databases.
In an effort to resolves these issues, the Cross-Linguistic Data Formats Initiative (CLDF) was created. In a paper published in Scientific Data, the CLDF sets out proposed guidelines for a standardized format for linguistic databases, and also supplies a software package, a basic ontology and usage examples of best practices. The goal of this effort is to facilitate sharing and re-use of data in comparative linguistics.
Standardizing data formats to facilitate sharing and reuse
The CLDF provides a data model underlying its recommendations that aims to be simple, yet expressive, and is based on the data model previously developed for the Cross-Linguistic Data project. This model has four main entities: (a) Languages; (b) Parameters; (c) Values; and (d) Sources. In the model, each Value is related to a Parameter and a Language, and can be based on multiple Sources. There are additionally References for Sources, and References can also have Contexts (which, for example, for printed references would be page numbers).
 illustrates why long tables should be favored throughout all applications. (b) underlines the importance of anticipating multiple tables along with metadata indicating how they should be linked.")
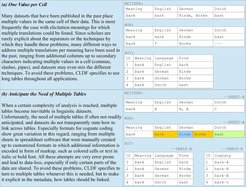
Basic rules of data coding included in the guidelines, taking cognate coding in wordlists as an example. (a) illustrates why long tables should be favored throughout all applications. (b) underlines the importance of anticipating multiple tables along with metadata indicating how they should be linked.
The CLDF data model is a package format, in which a dataset would be made up of a set of data files containing tables, and a descriptive file that defines the relationships between the tables. Each linguistic data type would have a CLDF module and additional components, which would be the aspects of the data in the module that recur across multiple data types. The CLDF modules would also contain terms from the CLDF ontology. The ontology is a list of vocabulary that represents objects and properties with well-known semantics in comparative linguistics. This makes it possible for users to reference these terms in a uniform way.
A software package to enable validation and manipulation
The CLDF specifications use common file formats – such as CSV, JSON and BibTeX – that are widely supported, with the goal that these files can easily be read and written on many platforms. Even more importantly, the standardized format will allow researchers without programming skills to access and manipulate the data with preexisting tools, rather than this ability being limited to researchers with sufficient programming skills to create their own tools. To facilitate this, the CLDF has created a “cookbook” repository for scripts for use with the CLDF specifications.
“We want to bring access to these data and the ability to compare them to as many researchers as possible,” states Johann-Mattis List of the Max Planck Institute for the Science of Human History. He also notes that the CLDF format is not limited to linguistic data alone, but can also incorporate databases of cultural and geographic data, for example. “CLDF may drastically facilitate the testing of questions regarding the interaction between linguistic, cultural, and environmental factors in linguistic and cultural evolution.”