Die Anwendung von Computermethoden auf große Datensätze wird in der historischen Linguistik immer wichtiger
Neue Studie weist eine Erfolgsrate von 89% für die automatische Entdeckung verwandter Wörter in Sprachfamilien auf
Der Vergleich unterschiedlicher Sprachen ist eine grundlegende Aufgabe der historischen Sprachwissenschaft. Sprachvergleiche erlauben es Linguisten, die Entwicklung von Sprachen über Tausende von Jahren zurück in die Vergangenheit zu verfolgen, lange bevor die Schrift erfunden wurde und schriftliche Aufzeichnungen die Existenz von Sprachen bezeugen. Wörter wie tooth im Englischen, Zahn im Deutschen, dente im Italienischen und dent im Französischen gehen alle auf dasselbe Vorgängerwort zurück. Genauso wie Biologen ausgestorbene Spezies rekonstruieren und Archäologen archaische Gesellschaften nachweisen, können Linguisten auch die Aussprache alter Wörter auf der Grundlage der heute existierenden Wörter erschließen und so zeigen, welche Sprachen von einem gemeinsamen Vorfahren abstammen. Linguistische Indizien spielen daher eine sehr wichtige Rolle für die Erforschung der Menschheitsgeschichte.
Während mehr und mehr große digitale Sammlungen von Sprachdaten erschlossen werden, konnte bisher nur ein Bruchteil der mehr als 7000 Sprachen, die heute in der Welt gesprochen werden, gründlich analysiert werden. Dies ist nicht verwunderlich, wenn man sich klar macht, dass die klassischen Vergleichsstudien in der Linguistik immer noch auf manueller Arbeit beruhen, die nur von einem kleinen Kreis qualifizierter Experten ausgeführt werden kann. “Mit der raschen Zunahme an zur Verfügung stehenden Daten erreichen die traditionellen Methoden ihre praktischen Grenzen”, sagt Johann-Mattis List. Nichtsdestotrotz gibt es nach wie vor ein dringendes Bedürfnis an Sprachvergleichsstudien. “In großen Teilen der Welt, wie in Neuguinea oder Südamerika, sind sowohl die Sprachen wie auch die Geschichte der Menschen, die diese sprechen, bisher kaum untersucht worden”, sagt List.

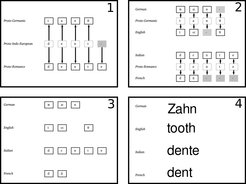
Algorithmen durchforsten riesige Sprachdatenbanken, um die Verwandtschaftsbeziehungen der heute gesprochenen Sprachen zu ermitteln. Diese können wir oft schon durch den Vergleich einzelner Wörtern nachweisen, wie in dieser Beispielgrafik, die die Entwicklung des Wortes "Zahn" in verschiedenen indogermanischen Sprachen zeigt.
Große Fragen, wachsende Datensätze, und riesige Probleme für Computeranalysen
Angesichts der großen Menge an linguistischen Datensätzen ist es verlockend, Computermethoden zu verwenden, um nach den Antworten auf die großen Fragen der Menschheitsgeschichte und kulturellen Entwicklung zu suchen. Das ist aber keinesfalls einfach. Im Gegensatz zu den gründlichen linguistischen Analysen, die ausgebildete, erfahrene Forscher mit sehr detailliertem Wissen zu spezifischen Sprachen durchführen, sind Computeralgorithmen blind gegenüber sprachspezifischen Eigenheiten und müssen entscheidende Parameter aus den Daten erschließen, die man ihnen füttert. Dies kann leicht dazu führen, dass die Computer falsche Ergebnisse liefern. “Computermethoden werden oft als ‘Blackbox’ kritisiert”, sagt Simon Greenhill, der zweite Autor der Studie. “Man kann wunderschöne Ergebnisse bekommen, aber man kann nicht wirklich evaluieren, wie gut und verlässlich diese sind. Was wir wirklich wissen wollen ist nicht nur, ob Sprachen verwandt sind, sondern auch, welche Indizien diese Annahme wirklich unterstützen.”
In ihrer Studie testete die von Russell Gray geleitete Forschungsgruppe verschiedene automatische Ansätze, die sich hinsichtlich ihrer analytischen Differenziertheit und Komplexität unterschieden – mit überraschend guten Ergebnissen. “Insgesamt waren unsere Ergebnisse relativ präzise”, sagt List. Aber: Während manche Algorithmen unter bestimmten Umständen sehr gute Trefferquoten lieferten, waren die Ergebnisse unter anderen Umständen mitunter auch sehr enttäuschend. Die beste der getesteten Methoden war ein neuer Ansatz, den das Team extra für die Studie entwickelt hatte. Dieser Ansatz erkannte Kognaten in Übereinstimmung mit Experten in 89,5% aller Fälle. “Im Gegensatz zur Angst vieler Experten, dass die automatischen Methoden eine große Anzahl falscher Positive produzierten, haben wir herausgefunden, dass das Gegenteil der Fall ist: Wenn der Algorithmus sagt, dass zwei Wörter verwandt sind, ist dies normalerweise korrekt”, sagt Greenhill.
Die Zukunft liegt im Zusammenspiel von Computern und Experten
Heißt das nun, dass Maschinen schon sehr bald die Experten in der Suche nach etymologisch verwandten Wörtern in den Sprachen der Welt ersetzen werden? Die Max-Planck-Gruppe hält dies nicht für eine gute Strategie. Anstatt ausschließlich auf Computer zu setzen, favorisieren sie computer-gestützte Ansätze, in denen Algorithmen für eine vorläufige Analyse verwendet werden und somit den Großteil von repetitiver und grober Arbeit übernehmen. Diese vorsortieren Ergebnisse können dann von Experten korrigiert und verfeinert werden. Für Russell Gray, Leiter der Studie, ist dies nur der Anfang: “Wir haben das volle Potenzial von Computermethoden in der historischen Linguistik noch lange nicht ausgeschöpft, und es ist fast sicher, dass zukünftige Algorithmen noch näher als bisher an die Expertenurteile heranreichenwerden”, sagt er. Aber Computer werden nie in der Lage sein, qualifizierte linguistische Experten zu ersetzen. Gray: “Computermethoden können sich um die repetitiven und schematischen Aufgaben kümmern. Auf diese Art erlauben sie es Experten, sich darauf zu konzentrieren, die wirklich interessanten Fragen zu lösen.“